Standup Comedy Analysis
Overview
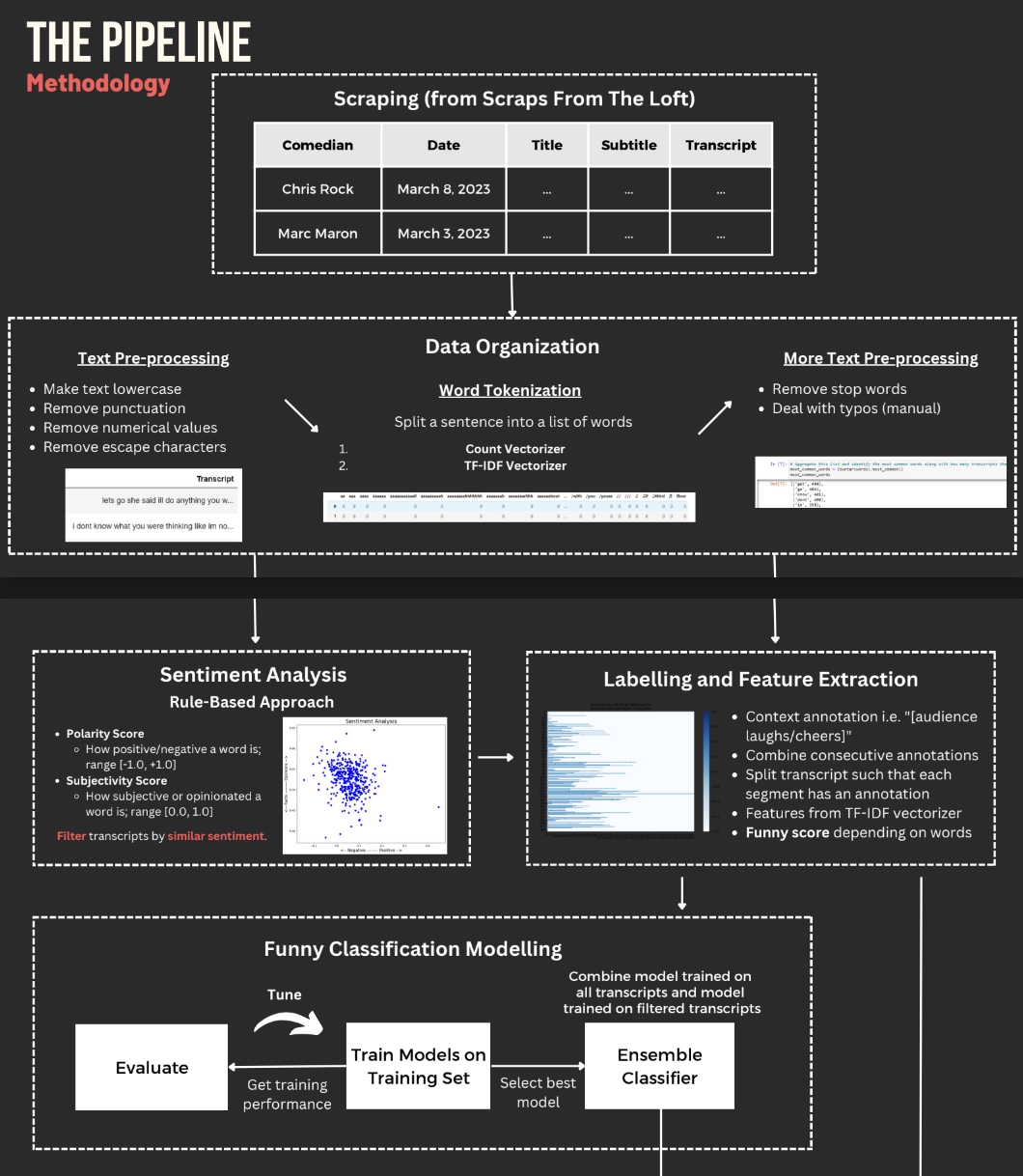
This project uses NLP techniques in text preprocessing - tokenization, lemmatization, Part-of-Speech tagging and TF-IDF Vectorizer. Sentiment analysis is performed to filter data and an ensemble classifier is used to model funniness. Results are displayed interactively using Streamlit. I encourage you to view the presentation slides (it’s nicely crafted) for a deep dive of our thought process and steps in the project.
Key Techniques : Natural Language Processing
Links :
Main Challenges
- Using the appropriate techniques with good reasonings behind our deceisions in text preprocessing - organizing the document-term matrix using TF-IDF instead of CountVectorizer, custom word tokenizer (custom stopwords list and lemmatize using POS tagging), implement TextBlob instead of Vader for sentiment analysis due to lower computational cost.
- Determine our own funniness formula for target labelling : Funny Score = 0.55*laugh + 0.25*applaud + 0.20*cheer
- Instead of using one model, we use a voting (ensemble) classifier with Random Forest, AdaBoost and Gradient Boosting for prediction. To attain optimal performing models, we used GridSearchCV to conduct hyperparameter tuning.
My Contributions
- I was mainly in charge of text-preprocessing tasks using NLP techniques (main challenge first bullet point) and assisted on the model evaluation.
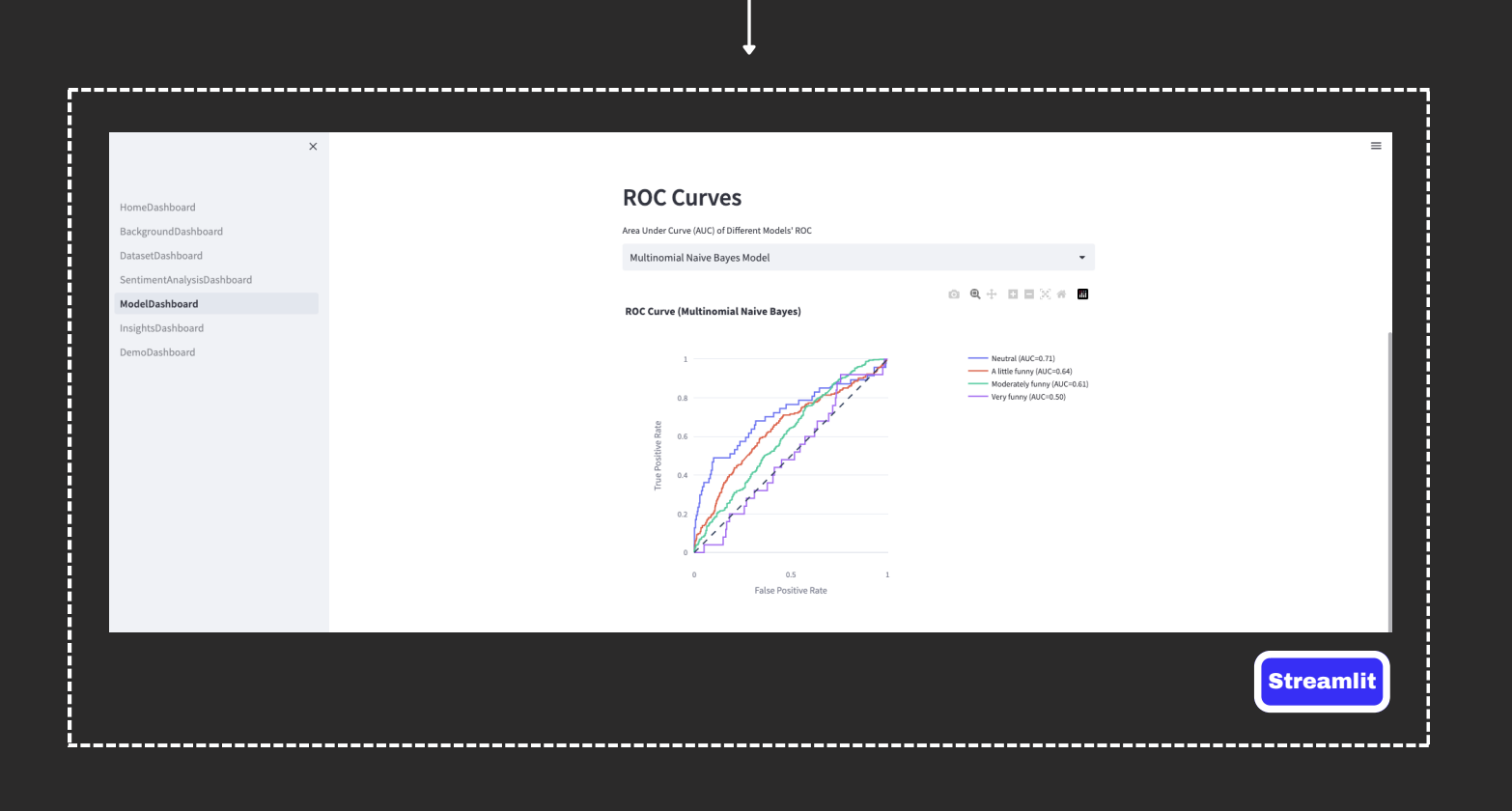
- I created a Streamlit dashboard to for interactive presentation (audience can scan QR code to try out the model). The app consists of interactive EDA, model performance, and demo of our project (input live transcript to determine funniness score).
Tech Stack
Python libraries - Beautiful Soup, NLTK, spaCy, TextBlob, Scikit-Learn, Matplotlib, Seaborn, Streamlit
Outcome & Impact
This project was my first NLP project in class. I gained a deeper understanding of language preprocessing which thereafter motivated me to take a higher level NLP class during student exchange.