Comparative Study of Quantization Aware Training for ViTs and CNNs

Overview
This project is a graduate research project from Gedas’s class on Vision Recognition with Transformers in UNC. Sizhe Liu is the graduate student leading the project and he ran mostly the experiments with Alex (undergraduate researcher). My main tasks were to evaluate and analyse the results and produce the visualisations across different experiments to be used in our presentations and paper.
What is Quantization Aware Training ?
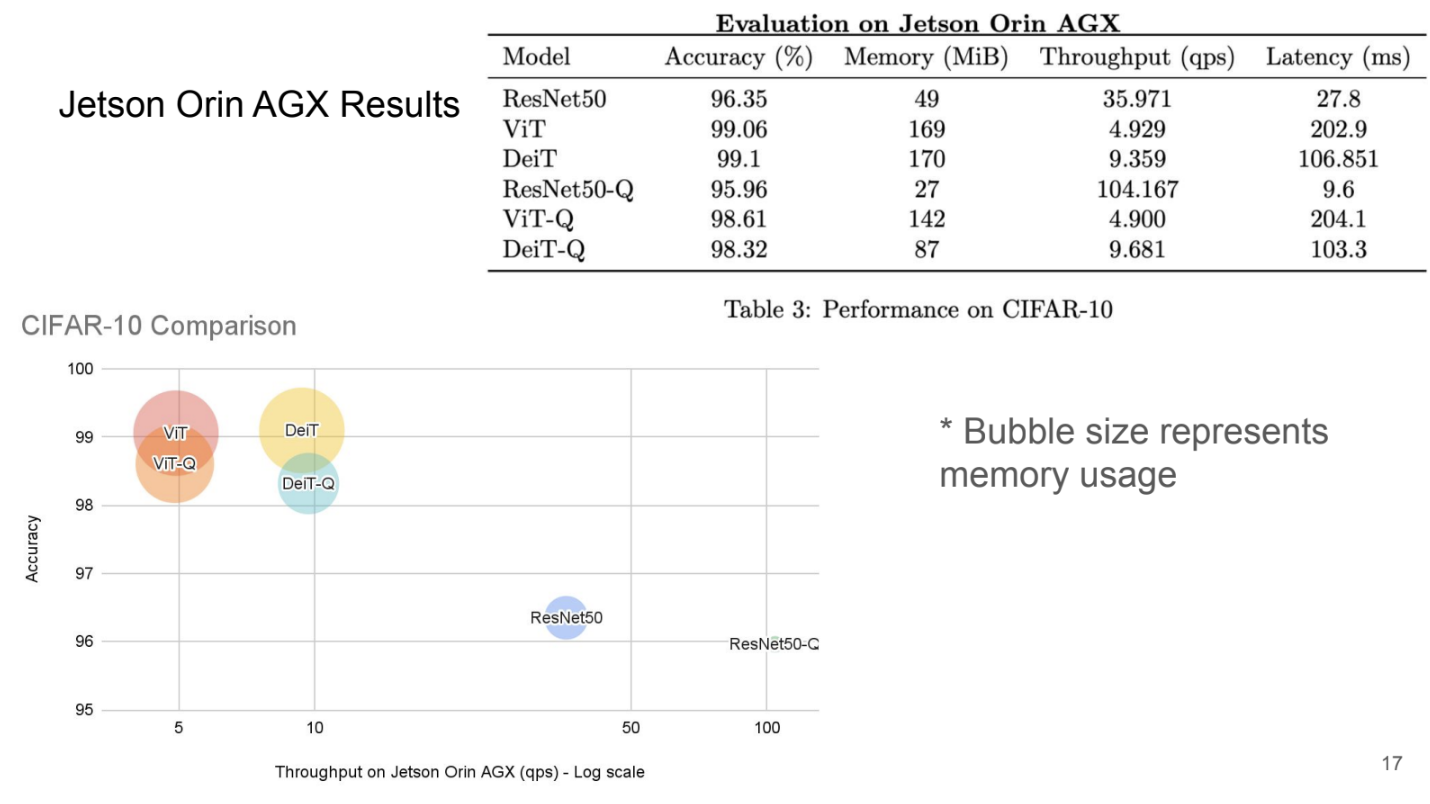
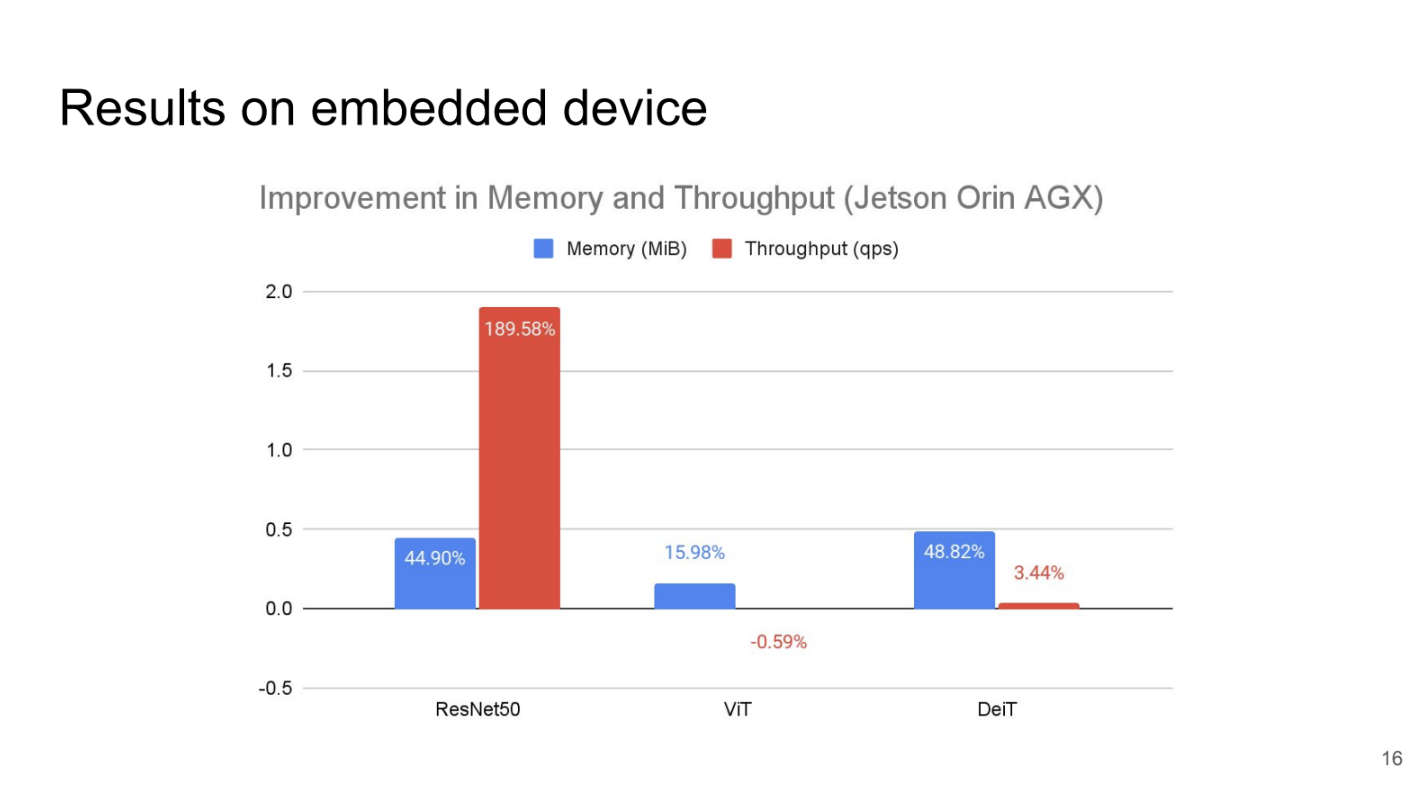
High capacity Vision Transformers contain up to billions of parameters making them difficult to be applied in embedded devices and real-time settings due to their low throughput and high memory usage. Quantization Aware Training reduces the precision of the model parameters (weights and activations) to lower bits, increasing throughput and use less memory. With QAT, we fine-tuned the model after applying quantization. In prior works, QAT is less studied in Vision Transformers and are also not compared to models with CNN architectures, which motivated us to conduct this comparative study of the impact of QAT on ViTS and CNNs. We also challenged ourselves to apply our quantized models on NVIDIA Jetson Orin AGX which yielded significant improvement in memory and throughput.
Key Techniques : Computer Vision, Quantization Aware Training
Link to paper : Comparative Study of Quantization Aware Training for ViTs and CNNs.
Link to final presentation here.
Main Challenges
- Acquire a high-level understanding of QAT motivation, techniques and technical implementation to define the goals of our study and choose suitable ViTs and CNNs for our study.
- Dive deeper into understanding the different components of ViTs and CNNs and how we can apply QAT to preserve their accuracy while increasing throughput.
My Contributions
- Together with Daniel, we reviewed many existing literatures and prior works on Quantization Aware Training to gain a deeper understanding of the debates and weaknesses of the topic before conducting the experiments.
- I worked on the visualisation (bar charts and bubble charts) of our experiment results to deliver accurate comparisons on the improvement of memory and throughput we observed after applying quantization on different ViTs and CNNs.
- Our team worked on the presentation slides and final paper collaboratively.
Outcome & Impact
This research project was an eye-opening experience for me to the computer vision domain and academia research area. Thanks to Sizhe’s and Alex’s expertise in CV techniques and their guidance along the way, our team (which are mostly undergraduates) could efficiently run experiments, evaluate the results and submit the paper. Gedas’s class introduced a variety of ViTs and their differences and applications which helped me understood CV and my project better.